Werewolf Among Us: Modeling Persuasion Behaviors in Social Deduction Games
The first multimodal benchmark dataset for modeling persuasive behaviors during social deduction games.
About
arXiv Code & Models DatasetsThis project presents the first multimodal dataset for persuasion strategy modeling, composed of video captures and dialogue transcriptions and collected in natural social scenarios including intensive in-person conversations of multiple players engaged in social deduction games like One Night Ultimate Werewolf. The dataset is annotated with appropriate persuasion strategies for every utterance in every game dialog and the voting outcomes of each game as an evidence of human's belief. We also implement and present comprehensive experiments of persuasion strategy prediction and voting outcome deduction.
Data Sources
We present two major sources of video captures of completed play-throughs of social deduction games in our dataset (all with explicit game outcomes and with the same game setup), based on which accurate corresponding dialogue transcriptions are created and also presented in our dataset:
- Ego4D: A subset of the Ego4D Social dataset captures the videos of a group of participants playing social deduction games. This subset contains 7.3 hours of videos with 40 games of One Night Ultimate Werewolf and 8 games of The Resistance: Avalon. We leverage only third-person videos from this dataset for transcription and experiments.
- YouTube: This subset captures 14.8 hours of 151 clips of completed games of One Night Ultimate Werewolf, extracted from publicly accessible YouTube videos with help of YouTube Data API V3. We release the YouTube URL's for this subset of videos.
Data Annotations
We present transcripts and comprehensive annotations for all completed games in our dataset applicable for a variety of tasks, most notably the tasks of persuasion strategy prediction and voting outcome deduction:
- Dialogue Transcripts High-quality human-reviewed dialogue transcripts of group conversations are provided for every video capture of every completed game in our dataset.
- Utterance-level Persuasion Strategies: The dialogue transcripts in our dataset additionally come with annotations of identified persuasion strategies for every utterance, based on the following strategy taxonomies that we have defined for conversations in social deduction games:
- Identity Declaration: State one's own role or identity in the game.
- Accusation: Claim someone has a specific identity or strategic behavior.
- Interrogation: Questions about someone's identity or behavior.
- Call for Action: Encourage people to take an action during the game.
- Defense: Defending oneself or someone else against an accusation or defending a game-related argument.
- Evidence: Provide a body of game-related fact or information.
- Game Dynamics: Our dataset also presents game-related annotations for every completed game, including the starting role, ending role, and the voting outcome of every participating player in a game.
Benchmarks
- Persuasion Strategy Prediction: To benchmark our dataset, we provide computational models trained on each subset of our dataset and comprehensive experimental results for the task of utterance-level prediction of persuasion strategies. We analyze the role of video modality and contextual cues when designing such models and provide additional results to show how different computational models generalize across different data sources and different games.
- Game Outcome Deduction: This task involves predicting the voting outcome of every player at the end of each game, for which we also provide baseline models trained on our dataset and corresponding experimental results.
Experiments - Context Length
We report average F-1 score results achieved for persuasion strategy prediction by every Base model with no previous context and the corresponding context model Base + C with different context lengths of 1, 3, 5, 7 and 9 previous utterances.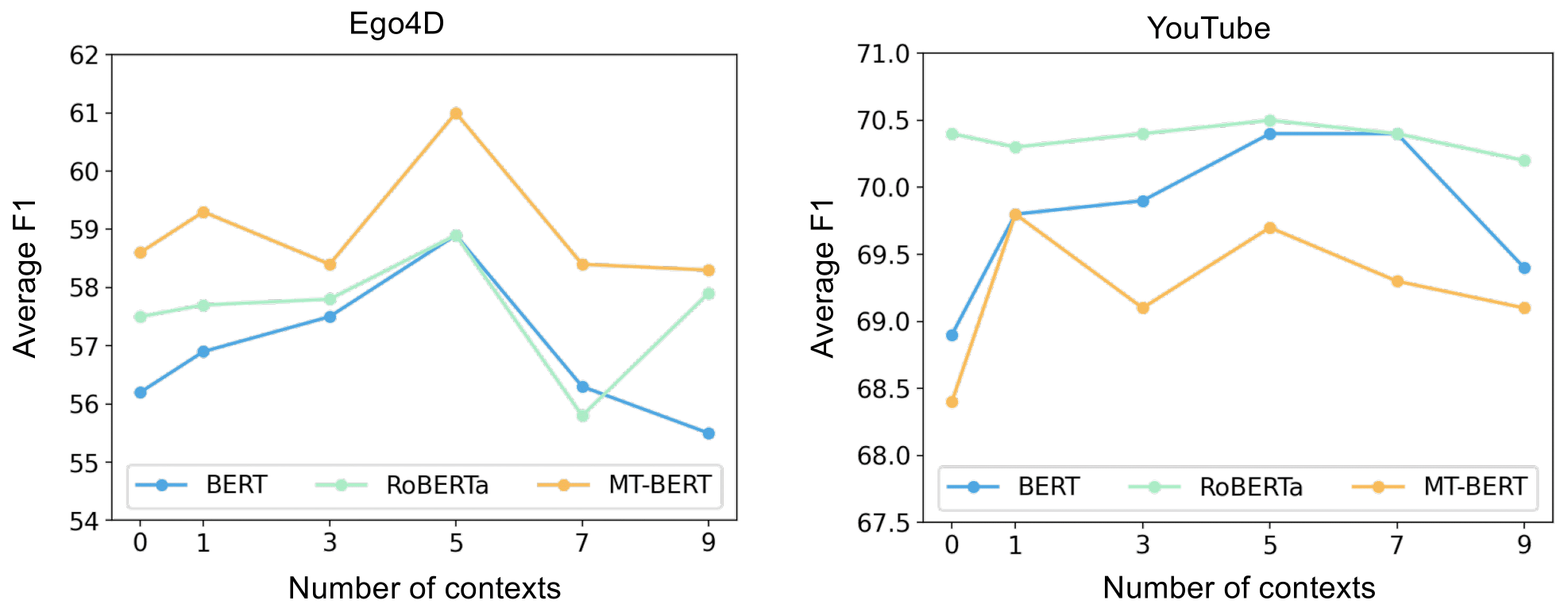
Experiments - Video Features
We report average F-1 score results for each subset of our dataset, achieved by our models for Base, context model Base + C, video model Base + V, and Base + C + V incorporating both video and context.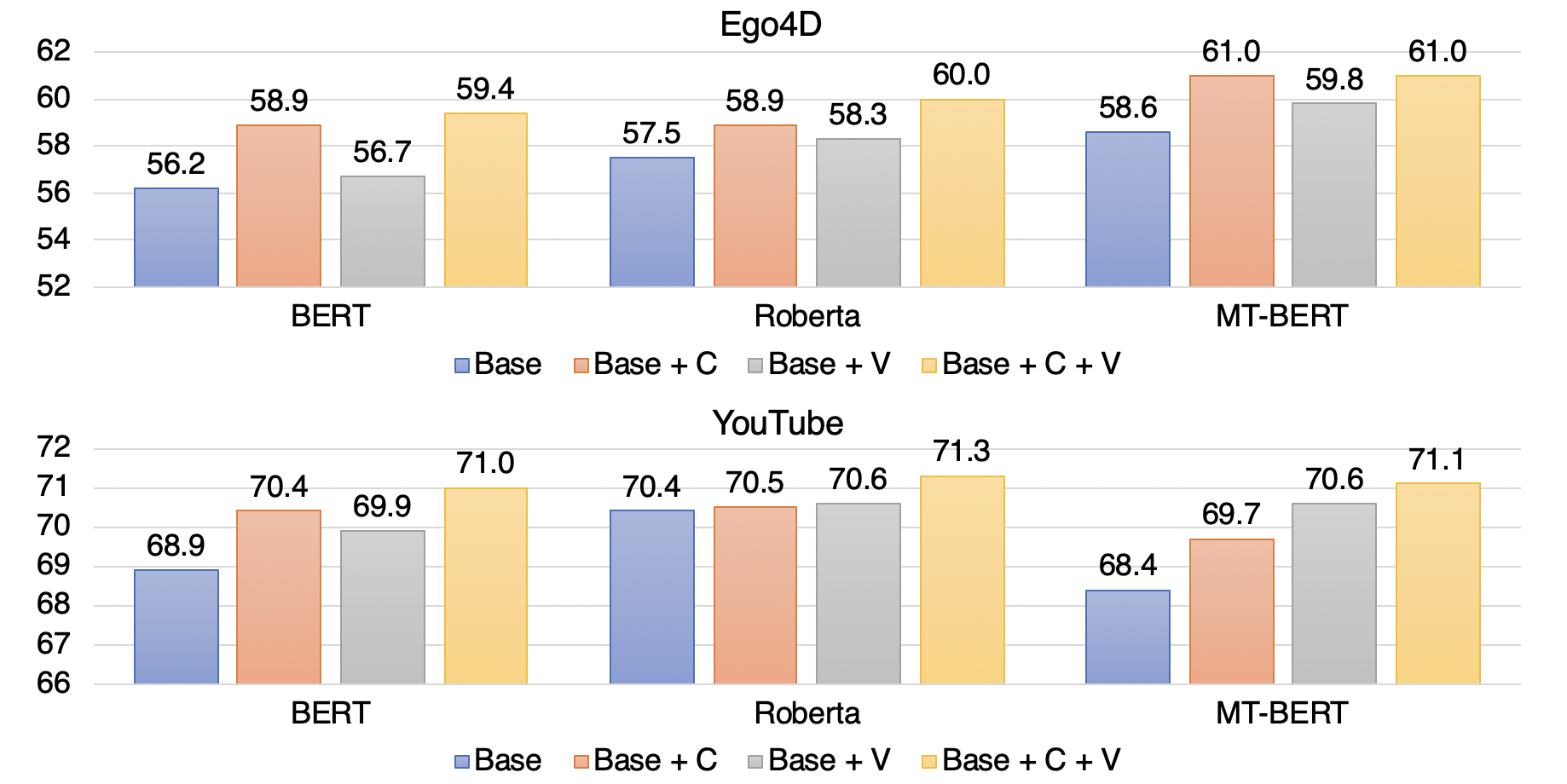
Experiments - Data Source Domain Generalization
We report average F-1 score results achieved by Base and context-based Base + C models trained on the much larger YouTube subset but tested on Ego4D subset without and after fine-tuning on Ego4D.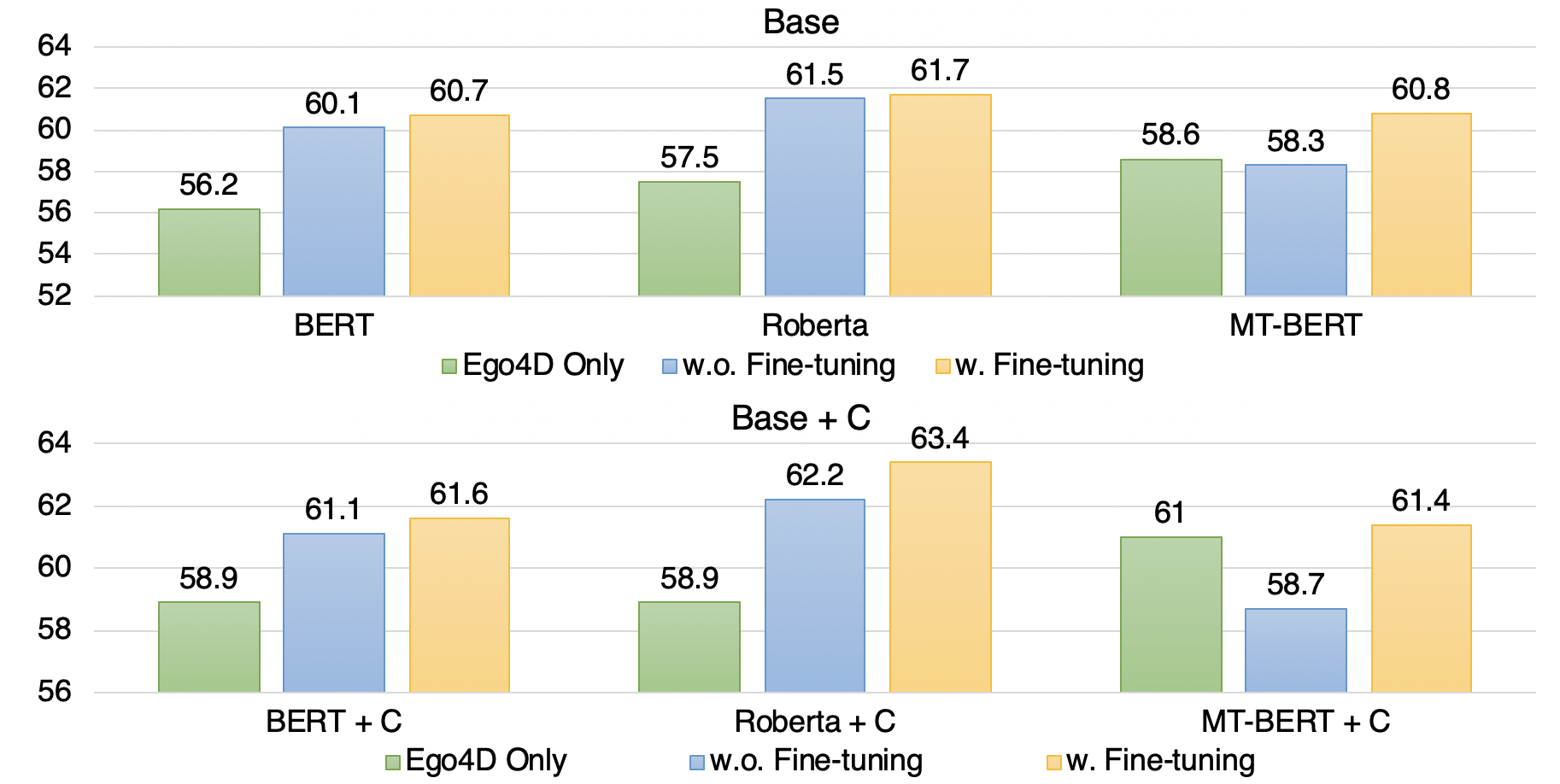
Experiments - Game Domain Generalization
We report average F-1 score results achieved by Base and context-based Base + C models trained on data for Werewolf games but tested on games of The Resistance: Avalon, a vastly different social deduction game.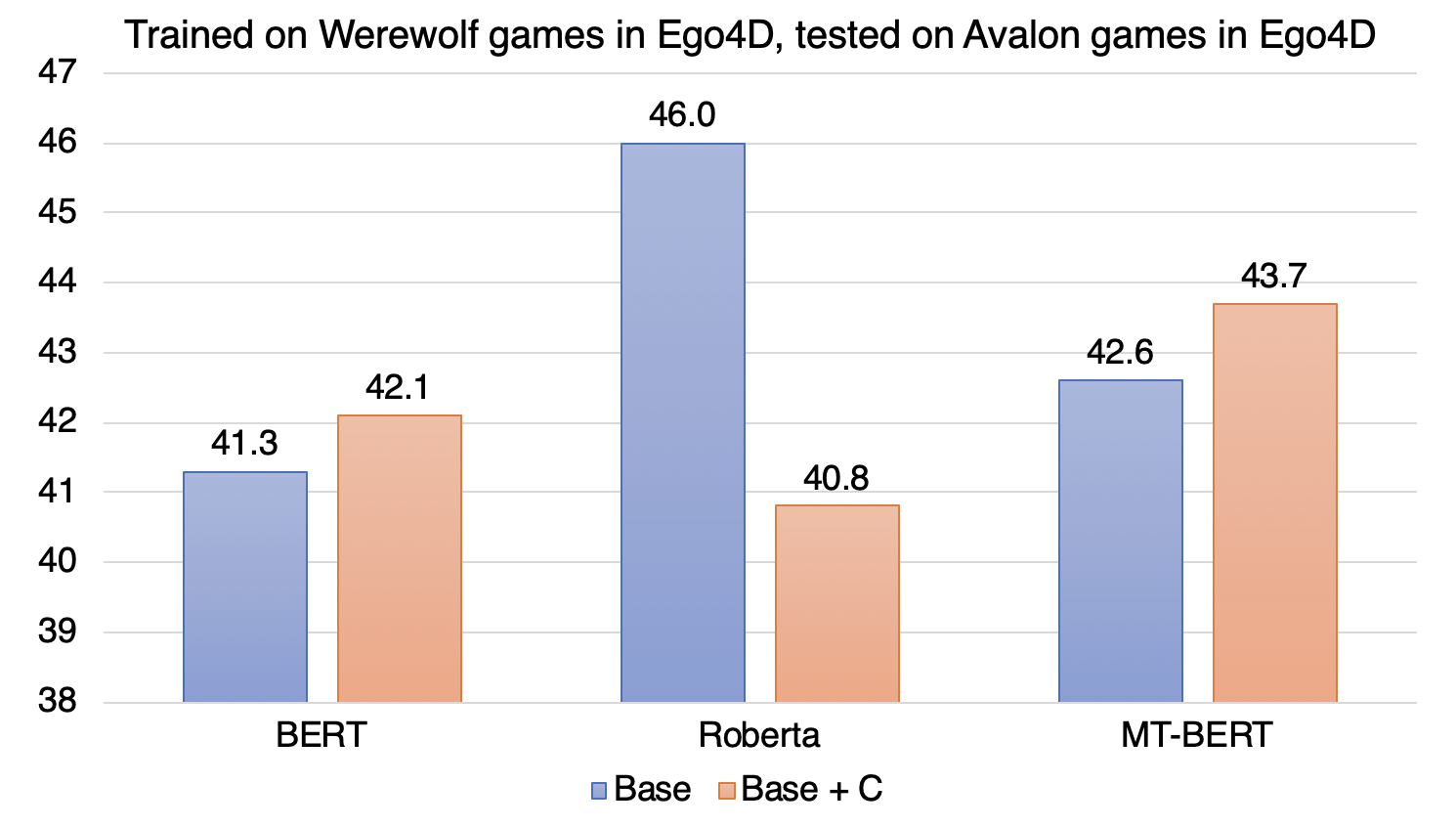
Experiments - Off-the-shelf GPT-3 Inference
We report average F-1 score results of experiments with OpenAI’s few-shot GPT-3 model on Ego4D and YouTube subsets under three learning settings: zero-shot, one-shot and five-shot.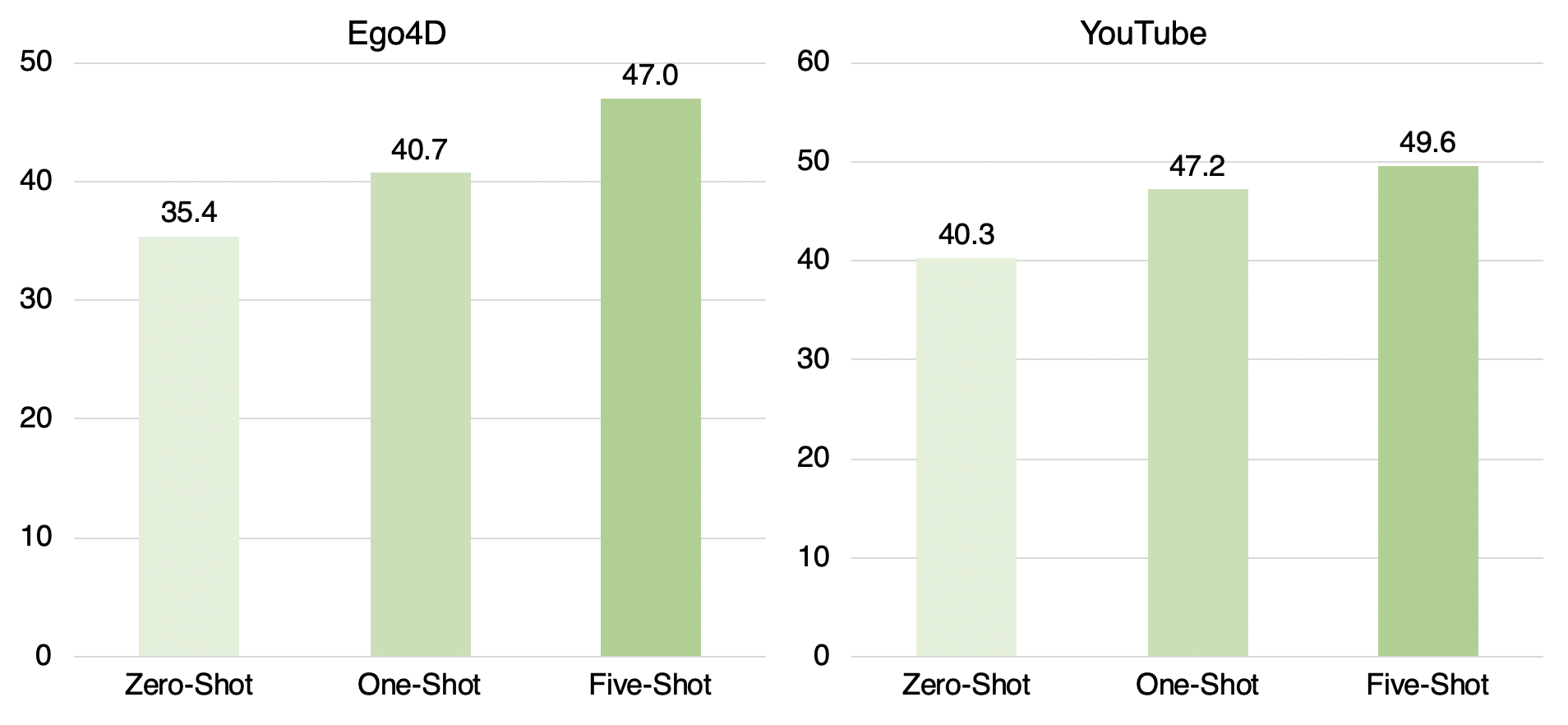
Coming Soon ...
Coming Soon ...